2025 年 8 月 4 日,在全球权威的 AI 性能基准评测组织 MLCommons® 颁发的最新一轮 MLPerf® Storage v2.0 基准测试中,中国存储厂商焱融科技全闪存储一体机 F9000X 给予亮眼表现。其在所有测试模型上均居于领先位置,并以三节点存储集群 513GB/s 的总带宽刷新了 3D-Unet 模型的记录,成功登顶全球性能榜单。
《MLPerfStorage》是评估深度学习AI存储性能的关键指标。
作为国际人工智能工程联盟,MLCommons 长期致力于推动并规范全球范围内 AI 技术准确性的提升、安全性及效率评估工作;同时也致力于通过 MLPerf Storage Benchmark 以真实模拟场景的 I/O 操作为基准,来精准衡量存储系统向 GPU 输送训练数据的能力。
此次发布的MLPerf Storage v2.0 在 v1.0 基础上进一步升级:除保留3D-Unet、ResNet50、CosmoFlow三大训练模型外,新增Checkpoint工作负载,更加全面地覆盖了训练中断点恢复、模型存档等实际应用场景。为了确保结果的严谨性和公正性,v2.0要求每项基准测试必须多次重复执行(每次训练任务均需5次执行,checkpoint任务则为10次),且整个测试进程始终连续进行而不会有任何失败。此外,所有测试过程都将被同步提交一份详实的测试日志,并最终将通过这些运行结果得出准确性的评估——一系列严格的规范使得v2.0成为了业界衡量AI存储性能时最具参考价值的标准。
焱融全闪的集群性能刷新了全球纪录,成为当前最小规模的分布式系统中的佼佼者。
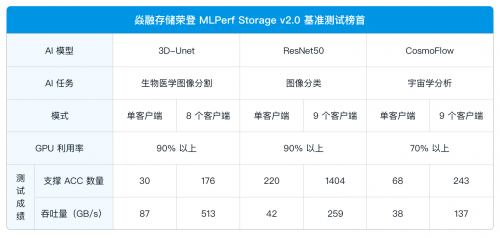
MLPerf Storage基准测试不仅适用于单个计算节点(客户端)同时运行多个AccGPU加速器的模型测试,也适合分布式训练集群场景,即通过多客户端模拟真实数据并行访问存储集群以覆盖从单节点到分布式集群全场景AI工作负载的工作负载。关键衡量指标包括性能,既在确保高性能GPU使用率(3D-Unet与ResNet50模型为90%,CosmoFlow模型为70%)的前提下,通过量化存储系统实现的聚合带宽。这一指标直接反映出实际能力的核心:是否充分“喂饱”计算资源避免造成GPU空闲浪费。私家侦探,侦探公司,调查公司,查人找物,商务调查,出轨外遇调查,婚外情调查,私人调查,19209219596
最新测试结果显示,在通用硬件环境中,针对分布式存储的最小规模集群,即三节点存储集群,焱融全闪 F9000X 在全球知名分布式存储厂商中脱颖而出,群集总带宽等关键指标位列第一,并且在 3D-Unet 模型测试中,集群带宽达到 513 GB/s ,为迄今已公布结果中的最高值。
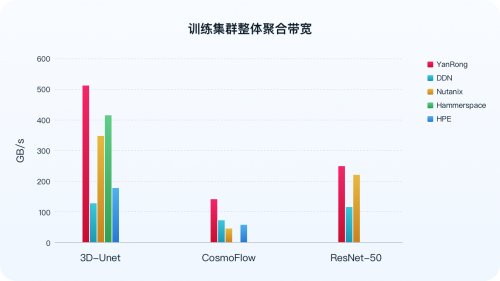
数据来源:MLCommns 官方 https://mlcommons.org/benchmarks/storage/
在分布式环境中也同样展现了非凡的性能,这进一步证实了它无论是在何种规模下都能够高效地执行数据处理任务。
此外,在新推出的CheckPoint工作负载测试中,针对Llama3-70B模型的场景部署8个客户端模拟并发请求以及64个模拟GPU环境实现读取带宽2.21 GB/s和写入带宽79 GB/s。这种稳定且高效的带宽支持能力使得Checkpoint文件在训练模型全流程中的读取与写入速度都能够达到秒级,底层存储层面为AI训练任务的断点续训连续性和模型训练稳定性提供了坚实的基础设施,帮助企业应对大规模训练任务中严苛的数据存储需求。
焱融存储MLPerf测试表现背后:技术积淀与生态协同是关键
据了解,去年焱融存储便参与了 MLPerf Storage v1.0 基准测试,并以出色成绩强势突围全球知名存储厂商。在 AI 大模型训练与推理等核心场景技术积累方面,焱融存储深耕多年。一方面通过持续深耕深入理解 AI 工作负载特性另一方面从架构设计到软硬件全技术栈持续推进系统性创新与优化构建起应对高性能负载的核心能力。
与此同时,焱融与NVIDIA、Intel、新华三(H3C)、忆恒创源(Memblaze)和大普微(DapuStor)等上下游生态伙伴共同参与深度协同,在网络芯片服务器、固态硬盘等领域进行紧密合作,实现软硬私家侦探,侦探公司,调查公司,查人找物,商务调查,出轨外遇调查,婚外情调查,私人调查,19209219596件的深入结合以及最优化,以确保系统在AI基础架构全链路中的高效稳定运行。
公开数据表明,焱融全闪存储得益于其独创的高效分布式文件管理系统YR Cloud File,凭借诸多核心技术实现了效能提升。
采用自主研发的Multi-Channel网络带宽聚合技术,能够无缝整合多块InfiniBand或RoCE网卡的性能,在处理海量数据时最大限度发挥硬件的效能。
系统具有负载感知功能,可以根据需求智能地转换成中断与轮询的工作模式,从而大大提高了IOPS性能。
在IO层面上,通过采用异步非阻塞设计方式,可以有效地减少上下文切换次数,从而增强并行处理能力。并且由于处理器核心资源得到了高效分配利用,线程调度开销也大为降低,能够支持高并发的数据处理需求,同时也能充分利用NVMe SSD的性能优势。
为了应对由大规模GPU集群所引发的网络阻塞现象,专门优化了其通讯协议,确保在处理大量数据时,能够维持通信效率,并且保证数据传递的稳定性。
随着大模型向万亿参数演进,存储作为底层支撑的性能需求进一步提升。焱融科技在MLPerf Storage v2.0测试中的优异表现,不仅展示了中国存储厂商的技术实力,也为AI基础设施性能优化提供了借鉴路径。业内普遍预计,未来高带宽、低延迟的能力依然是支持大模型广泛落地的关键优势。
顶: 4踩: 1146






评论专区