MLPerf存储模拟实际存在的人工智能和机器学习工作负载。这些测试旨在提供关于人工智能存储架构的相关数据分析给参与单位,帮助其更全面地评估他们的AI解决方案。
结果摘要
在进行测试时,我们尝试使用模拟的H100GPU来执行3DUNet基准测试。
请注意,我们之前提交的以及用于替代基准配置的信息可在 ML-Perf for Storage Benchmark Results 技术报告中查到。
3D U-Net 模拟医学图像分割工作负载属于 MLPerf 存储基准测试中带宽密集型的,它突出了并行 I/O 吞吐量以及内存和 CPU 效率。测试分别包含了 1、3 和 5 个 Tier 0 节点三种配置。下表与图表总结了结果
"节点层的数量 "的零号层
支持 H100 GPU
吞吐总量
平均使用率
变异数
1
28
85.6 GB /秒
94.7%
百分之一千四百零二
3
八十四
大约是两千五百三十九兆一吉比特每秒
95.0 %
百分之零点一三
5
140
420.8 GB /秒
96.4%
百分之零点零八
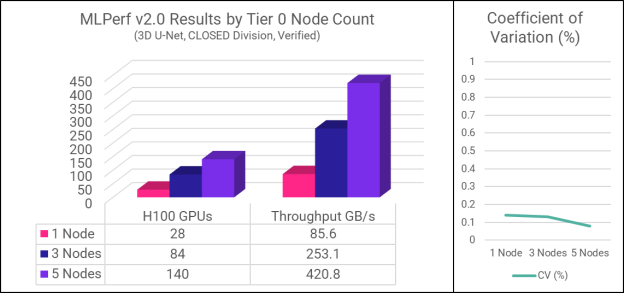
请注意,请支持的 GPU 数量以及其吞吐量都会按照第 0 层节点数量成线性比例增加。这种设计展示了主数据集100%驻留在主机上的最佳状况,且可以全部利用的最佳条件下的所有功能。随着集群规模的增长,峰值性能将取决于系统的配置与本地驻留数据百分比,但聚合性能也会随之扩展,这是我们的测试团队亟须进一步研究的领域。
平均GPU利用率意味着GPU使用率和空闲时间之间的百分比关系。要通过MLPerf存储基准测试,所有GPU必须维持至少90%的利用率。这样越高越好,目标是最大程度减少GPU空闲时间。
变异系数(CV)是一个衡量同一测试的不同次运行之间结果差异的度量。为了保证测试结果的真实性和可靠性,MLPerf Storage基准测试要求每次执行测试时进行多次运行,并保持结果在很小的范围内。这个步骤确保了测试结果是可重复且可靠的标准。Hammerspace的结果显示极低的CV值表明系统的性能非常稳定且可预测性强。
竞争比较 – 简单性和效率是关键为确保有意义和公平的比较,以下讨论仅包括使用本地共享文件配置执行 3D U-Net H100 测试的供应商。此图显示了每个供应商在支持的 GPU 数量方面提交的最佳结果:

如您所见,Hammerspace Tier 0 在测试中取得非凡成绩,战胜了许多知名品牌。私家侦探,侦探公司,调查公司,查人找物,商务调查,出轨外遇调查,婚外情调查,私人调查,19209219596不过,还有一种看待其表现的视角是不可忽视的:通过对效率的理解和分析,它呈现出令人印象深刻的启发性和关联性。
全球数据中心普遍面临电力供应不足、高温控制不佳以及空间受限等问题。为确保数据中心的运行稳定,需要高性能的能源消耗。而人工智能及其使用的GPU服务器的能耗水平使得这个问题尤为严重。换句话说,高效的能源管理至关重要。
对于“存储”的测试结果并不准确,但我们可以通过 rack U 来模拟这种需求,也就是更多的 rack U 会占用更多电力。

查看各个额外存储基础架构机架U支持的GPU数量,HammerSpace Tier 0在所有系统中遥遥领先,并且导致效率最高系统的三倍。
实际中GPU服务器,也就是这里的基准测试客户端正在运行AI工作负载。而“额外机架U”,则指存储解决方案除了与计算服务器相连的空间外,在其外部还有额外使用的空间量。
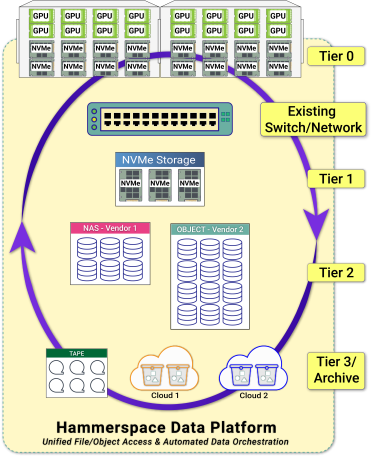
由于位于第 0 层聚合集群中的本地 NVMe 存储用于基准测试,我们所需的唯一额外硬件就是单个1U的元数据服务器,在 Hammerspace 中称为 Anvil。在生产安装中通常运行两个 Anvil来实现高可用性,但即使如此,Hammerspace 的效率也会比下一个最佳入口高出85%。
通过查看最大GB/s 带宽我们可以了解到类似情况:HammerSpace Tier 0 的吞吐量是下一较近的出口流量的三倍多一点。

下面是测试配置的示意图,它显示了基准配置。
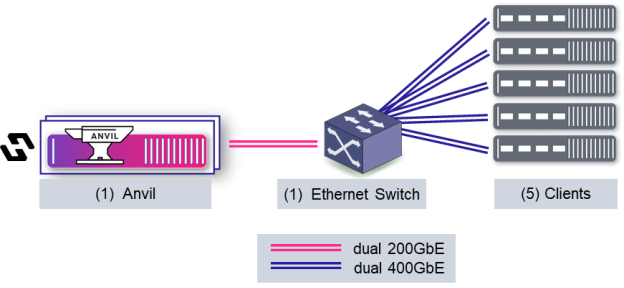
客户端执行基准测试代码,第 0 层私家侦探,侦探公司,调查公司,查人找物,商务调查,出轨外遇调查,婚外情调查,私人调查,19209219596将容纳 NVMe 驱动器——在该例中,每个客户机将有10个ScaleFlux CSD5000驱动器。Anvil负责元数据和集群协调任务——没有数据流经过它。客户端通过并行 NFS v4.2挂载共享文件系统,在接收到Anvil的布局后直接访问存储。
基础架构在可利用的有限范围内具有人为成分。通常而言,顶层通常为哈梅斯空间的基础结构中的众多共享层次之一,并可能包括跨多个站点或云中连接的第1层NVMe和对象存储等层次。
为什么第0层对企业AI至关重要随着企业考虑AI计划,初始成本迫在眉睫。为了获得计算资源和存储空间,并识别、清理和组织来自整个组织的大量数据,任何可以简化这一入门的东西都是有价值的。这就是为何MLPerf v2.0致力于我们的第0层实施。
Hammerspace级零激活已存在的NVMe存储设备,将它们带入共享的全局命名空间。利用Hammerspace广泛的数据布局功能自动生成并保护这些数据。如果在云计算环境中租用比购买更经济合理的话,第0层甚至能在云中工作。
对于数据整理的关键起步阶段来说Hammerspace中的同化功能无需在优化前对大量原始数据在全新库中复制。而是通过扫描现有NAS卷元数据将其带入Hammerspace。数据本身保持不变。一旦识别并准备了相关数据,就可以将它们动态地分配到高性能存储层如第0层上进行处理最后将其存档到成本较低的层面。

Tier 0 for Enterprise AI的优势Hammerspace Tier 0 for Enterprise AI 的优势包括:
单纯:
利用既有的存储和网络基础设施进行开发就无需再安装任何代理程序并且没有额外需要的网络条件仅需要使用以太网即可。
效能
相比普通文件存储,第0层提供的性能可以提升10倍。它大大提升了本地和云端的工作效率,并优化了GPU的使用方式以及更快的检查点处理过程,从而有效地减少了推理的时间。
效率:
将较少的外接储存空间用于外接储存相较于外接储存,功耗、机房空间及传输时间都较低地完成有价值 – 可在几个小时激活第 0 层而非几天或几周
顶: 5踩: 1727






评论专区