пјҲеҜјиҜӯпјүAI иҝҗз®—иғҪеҠӣеҸҲиҫҫеҲ°дәҶдёҖдёӘе…Ёж–°зҡ„ж°ҙе№ігҖӮ
йҡҸзқҖAIеӨ§жЁЎеһӢеҠ йҖҹиҝӯд»ЈпјҢжҷәиғҪз®—еҠӣжҲҗдёәзЁҖзјәиө„жәҗпјҢиҖҢз®—еҠӣдҪңдёәдәәе·ҘжҷәиғҪеҸ‘еұ•зҡ„еҹәзҹіпјҢжҳҜи®ӯз»ғе’ҢжҺЁзҗҶиҝҮзЁӢдёӯзҡ„ж ёеҝғиғҪйҮҸж¶ҲиҖ—гҖӮдј з»ҹдёҠйҖҡз”Ёзҡ„и®Ўз®—иө„жәҗеҫҲйҡҫж»Ўи¶іиҝҷдәӣеӨ§и§„жЁЎжЁЎеһӢеҜ№и®Ўз®—иғҪеҠӣзҡ„йңҖжұӮпјҢеӣ жӯӨжӢҘжңүејәеӨ§еҸҜйқ AIз®—еҠӣеҹәзЎҖе№іеҸ°жҳҫеҫ—е°ӨдёәйҮҚиҰҒгҖӮ
дәәе·ҘжҷәиғҪжӯЈеңЁиҝ…йҖҹеҗ‘жӣҙеӨҡзҡ„йўҶеҹҹжӢ“еұ•пјҢ并且许еӨҡдј з»ҹдјҒдёҡе·Із»ҸејҖе§ӢеҲ©з”Ёдә‘и®Ўз®—е№іеҸ°жқҘж”№иҝӣ他们еңЁCPUдёҠзҡ„AIеә”з”ЁзЁӢеәҸгҖӮ
дҫӢеҰӮпјҢеңЁй«ҳеәҰеӨҚжқӮ并且иҠұиҙ№иҫғй•ҝж—¶й—ҙзІҫзЎ®еәҰжһҒй«ҳзҡ„з‘•з–өжЈҖжөӢйўҶеҹҹпјҢеј•е…ҘдәҶCPUе’Ңе…¶д»–з”өеӯҗдә§е“Ғз»„иЈ…дҪ“пјҢз”ЁдәҺжһ„е»әи·Ёи¶ҠвҖңдә‘з«ҜвҖ”иҫ№зјҳвҖ”з«ҜвҖқзҡ„дәәе·ҘжҷәиғҪзјәйҷ·жЈҖжөӢзі»з»ҹгҖӮ
жҜ”еҰӮдәҡдҝЎз§‘жҠҖе°Ҷе…¶иҮӘ家OCR-AIRPAж–№жЎҲдёӯзҡ„CPU硬件平еҸ°иҝҗз”Ёе…¶дёӯпјҢе®һзҺ°д»ҺеҸҢзІҫеәҰжө®зӮ№пјҲFP32пјүеҲ°е®ҡзӮ№ж•°гҖҒж ҮеҮҶйҮҸеҢ–пјҲINT8/BF16пјүгҖҒеңЁеҸҜжҺҘеҸ—зҡ„зІҫзЎ®жҖ§жҚҹеӨұдёӢжҸҗеҚҮеҗһеҗҗйҮҸ并еҠ еҝ«жҺЁзҗҶзҡ„иҝҮзЁӢгҖӮдәәе·ҘжҲҗжң¬дёӢйҷҚиҮіеҺҹжқҘзҡ„еӣӣеҲҶд№ӢдёҖеҲ°дёүеҲҶд№ӢдёҖпјҢж•ҲзҺҮжҸҗеҚҮи¶…иҝҮдә”еҖҚз”ҡиҮіжӣҙеӨҡгҖӮ
еңЁеӨ„зҗҶдәәе·ҘжҷәиғҪеҲ¶иҚҜйўҶеҹҹиҮіе…ійҮҚиҰҒзҡ„дёҖз§Қз®—жі•пјҢAlphaFold2иҝҷзұ»еӨ§еһӢжЁЎеһӢдёҠ,CPUд№ҹе·ІвҖңе…ҘзҫӨвҖқгҖӮиҮӘеҺ»е№ҙејҖе§Ӣ,CPUдҫҝдҪҝеҫ—AlphaFold2з«ҜеҲ°з«Ҝзҡ„еҗһеҗҗйҮҸжҸҗеҚҮеҲ°дәҶеҺҹжқҘзҡ„23.11еҖҚ;еҰӮд»Ҡ,иҝҷж•°еҖјеҸҲеҶҚж¬ЎжҸҗеҚҮиҮі204еҖҚгҖӮ
иҝҷдәӣCPUйғҪиў«з§°дёәиӢұзү№е°”В®пёҸиҮіејәВ®пёҸеҸҜжү©еұ•еӨ„зҗҶеҷЁ
дёәд»Җд№Ҳиҝҷдәӣдәәе·ҘжҷәиғҪд»»еҠЎзҡ„жҺЁзҗҶеҸӘиғҪиў«CPUжү§иЎҢпјҢиҖҢдёҚиҖғиҷ‘дҪҝз”ЁеӣҫеҪўеӨ„зҗҶеҷЁ (GPU) жҲ– AI еҠ йҖҹеҷЁжқҘиҝӣиЎҢе‘ўпјҹ
й•ҝжңҹд»ҘжқҘиҝҷйҮҢдёҖзӣҙеӯҳеңЁдёҚе°‘еҲҶжӯ§гҖӮ
жҚ®и®ёеӨҡдәәзңӢжқҘ,зңҹжӯЈжңүж•Ҳзҡ„AIжҠҖжңҜйҖҡеёёйғҪдёҺдёҖдёӘе…¬еҸёиҮіе…ійҮҚиҰҒзҡ„ж ёеҝғдёҡеҠЎзҙ§еҜҶзӣёиҝһгҖӮиҝҷзұ»еә”з”ЁйңҖиҰҒиҫғй«ҳзҡ„жҺЁзҗҶиғҪеҠӣпјҢ并且иҰҒжұӮиғҪеӨҹдёҺе®ғ们жүҖдҫқиө–зҡ„ж ёеҝғж•°жҚ®е…іиҒ”иө·жқҘпјҢиҝҷд№ҹж„Ҹе‘ізқҖеңЁйғЁзҪІAIзі»з»ҹж—¶еҜ№е®үе…ЁжҖ§жңүзқҖиҫғй«ҳиҰҒжұӮгҖӮеӣ жӯӨ,иҝҷзұ»еә”з”ЁжӣҙеҖҫеҗ‘дәҺжң¬ең°еҢ–йғЁзҪІгҖӮ
й’ҲеҜ№иҝҷдёҖйңҖжұӮпјҢз»“еҗҲдәҶдј з»ҹиЎҢдёҡзҡ„зү№зӮ№пјҢжӣҙзҶҹжӮүAIжҠҖжңҜ并иғҪиҪ»жқҫеҲ©з”ЁCPUзҡ„дјҒдёҡе°ҶеҸ—зӣҠдәҺжңҚеҠЎеҷЁз«Ҝж”ҜжҢҒж··еҗҲзІҫеәҰиҝҗз®—зҡ„ж–№ејҸгҖӮиҝҷз§Қи§ЈеҶіж–№жЎҲдёҚд»…жҸҗй«ҳдәҶеӨ„зҗҶйҖҹеәҰпјҢ并且з”ұдәҺе…¶жҲҗжң¬жӣҙдҪҺпјҢеӣ жӯӨеҜ№дәҺж»Ўи¶іиҮӘиә«иҰҒжұӮзҡ„иғҪеҠӣжӣҙејәгҖӮ
йқўеҜ№жӣҙеӨҡеҹәдәҺдә‘и®Ўз®—зҡ„дј з»ҹAIеә”з”Ёд»ҘеҸҠи¶…еӨ§и§„жЁЎиҜӯиЁҖжЁЎеһӢиғҪеӨҹеңЁCPUдёҠе®һзҺ°жңүж•ҲеҲ©з”Ё,дҪҝз”ЁCPUеҠ йҖҹAIжҲҗдёәдәӢе®һиҜҒжҳҺдәҶдёҖжқЎж–°зҡ„и·Ҝеҫ„гҖӮж•°жҚ®дёӯеҝғдёӯзҡ„иҝҷдёҖжҜ”дҫӢиЎЁжҳҺиӢұзү№е°”В® иҮіејәВ® еҸҜжү©еұ•еӨ„зҗҶеҷЁ70%зҡ„жҺЁзҗҶе·ҘдҪңиҝҗиЎҢдәҺжӯӨгҖӮ
жңҖж–°ж¶ҲжҒҜиЎЁжҳҺпјҢIntelзҡ„жңҚеҠЎеҷЁCPUе®һзҺ°дәҶеҶҚдёҖж¬ЎеҚҮзә§пјҢиҜҘе…¬еҸёеңЁ12жңҲ15ж—ҘеҸ‘еёғдәҶжңҖж–°зҡ„第дә”д»ЈиҮіејәеҸҜжү©еұ•еӨ„зҗҶеҷЁгҖӮиӢұзү№е°”ејәи°ғжҢҮеҮәпјҢж–°дёҖд»ЈеӨ„зҗҶеҷЁдё“й—Ёи®ҫи®Ўз”ЁдәҺеҠ йҖҹдәәе·ҘжҷәиғҪеә”з”ЁпјҢ并且其жҖ§иғҪжӣҙдёәејәеӨ§гҖӮ

дәәе·ҘжҷәиғҪжӯЈй©ұеҠЁзқҖдәәе’Ң科жҠҖдә’еҠЁж–№ејҸж №жң¬жҖ§зҡ„йқ©е‘ҪпјҢиҝҷз§ҚеҸҳйқ©зҡ„ж ёеҝғдҫҝжҳҜи®Ўз®—иғҪеҠӣгҖӮ
иӢұзү№е°”CEOеҹәиҫӣж јпјҲPat GelsingerпјүеңЁ2023иӢұзү№е°”ONжҠҖжңҜеҲӣж–°еӨ§дјҡиЎЁзӨәпјҡвҖңеңЁиҝҷдёӘдәәе·ҘжҷәиғҪжҠҖжңҜдёҺдә§дёҡж•°еӯ—еҢ–иҪ¬еһӢйЈһйҖҹеҸ‘еұ•зҡ„ж—¶д»ЈпјҢиӢұзү№е°”дёҖзӣҙз§үжҢҒй«ҳеәҰзҡ„иҙЈд»»ж„ҹпјҢдёәејҖеҸ‘иҖ…еҠ©еҠӣпјҢеңЁдәәе·ҘжҷәиғҪзҡ„иҝҗз”ЁдёҠпјҢи®©AIж— жүҖдёҚеңЁпјҢжӣҙжҳ“и§ҰиҫҫгҖҒеҸҜи§Ғдё”йҖҸжҳҺпјҢе…¶иЎҢдёәеҖјеҫ—дҝЎиө–гҖӮвҖқ
第дә”д»ЈиҮіејә дёәAIеҠ йҖҹ
Intel第дә”д»ЈиҮіејәеҸҜжү©еұ•еӨ„зҗҶеҷЁе…ұжңү64дёӘж ёеҝғпјҢжҗӯиҪҪдәҶиҫҫ320MBзҡ„L3зј“еӯҳд»ҘеҸҠ128MBзҡ„L2зј“еӯҳгҖӮ私家侦探пјҢ侦探公司пјҢ调查公司пјҢ查人找物пјҢ商务调查пјҢ出轨外遇调查пјҢ婚外情调查пјҢ私人调查пјҢ19209219596зӣёеҜ№дәҺд»ҘеҫҖзҡ„дә§е“ҒиҖҢиЁҖ,第е…ӯд»Јдә§е“ҒеңЁеҚ•ж ёжҖ§иғҪе’Ңж ёеҝғж•°йҮҸдёҠеқҮжңүжҳҺжҳҫжҸҗеҚҮ.дёҺдёҠдёҖд»ЈеӨ„зҗҶеҷЁзӣёжҜ”,еҠҹиҖ—дёӢе…¶жңҖз»ҲжҖ§иғҪжңүиҝ‘21%зҡ„жҸҗй«ҳ,еҶ…еӯҳеёҰе®ҪеҲҷжҸҗеҚҮдәҶ16%пјҢдёүзә§зј“еӯҳе®№йҮҸжӣҙжҳҜиҫҫеҲ°дәҶеҺҹжқҘзҡ„3еҖҚе·ҰеҸігҖӮ

йҮҚиҰҒзҡ„жҳҜпјҢжҜҸ颗第д№қд»Јй…·зқҝеӨ„зҗҶеҷЁйғҪйӣҶжҲҗжңүAIеҠ йҖҹеј•ж“ҺпјҢеӣ жӯӨе®ғиғҪеӨҹиғңд»»жһҒй«ҳзҡ„AIи®Ўз®—д»»еҠЎгҖӮзӣёжҜ”дәҺеүҚдёҖд»ЈпјҢе…¶и®ӯз»ғеҠҹиғҪжҸҗеҚҮдәҶ29%пјҢиҖҢжҺЁзҗҶиғҪеҠӣжӣҙжҳҜеўһй•ҝдәҶ42%гҖӮ
иӢұзү№е°”В® иҮіејәВ® еҸҜжү©еұ•еӨ„зҗҶеҷЁзҡ„жҳҫи‘—дјҳеҠҝдҪ“зҺ°еңЁеҜ№йҮҚиҰҒи®Ўз®—д»»еҠЎзҡ„еӨ„зҗҶиғҪеҠӣж–№йқўгҖӮ
Intelйқўеҗ‘ж·ұеәҰеӯҰд№ д»»еҠЎдёә第еӣӣд»ЈиҮіејәеҸҜжү©еұ•еӨ„зҗҶеҷЁеёҰжқҘдәҶдёҖйЎ№ж”№иҝӣпјҡзҹ©йҳөеҢ–з®—еҠӣж”ҜжҢҒпјҢж—ЁеңЁжҸҗй«ҳиҝҷдәӣй«ҳжҖ§иғҪеӨ„зҗҶеҷЁеңЁеӨ„зҗҶAIиҙҹиҪҪж–№йқўзҡ„ж•ҲзҺҮгҖӮ
AmxжҳҜIntelВ®пёҸеӨ„зҗҶеҷЁзҡ„дё“й—ЁеҢ–зҹ©йҳөиҝҗз®—еҚ•дҪҚпјҢе°ұеғҸжҳҜCPUйҮҢзҡ„ Tensor CoresпјҢиҮӘ第еӣӣд»ЈиҮіејәВ®еҸҜжү©еұ•еӨ„зҗҶеҷЁиө·е°ұжҲҗдёәеҶ…зҪ®еңЁCPUдёӯзҡ„дё“жңүAIеҠ йҖҹ组件дәҶгҖӮ
第дә”д»ЈиҮіејәеҸҜжү©еұ•еӨ„зҗҶеҷЁйҮҮз”ЁиӢұзү№е°”AMXе’ҢиӢұзү№е°”AVX-512жҢҮд»ӨйӣҶпјҢиғҪдёҺжӣҙеҝ«зҡ„еҶ…ж ёд»ҘеҸҠжӣҙеҝ«йҖҹеәҰзҡ„еҶ…еӯҳй…ҚжҗӯпјҢ并且еҸҜд»ҘеӨ§е№…жҸҗеҚҮз”ҹжҲҗејҸAIиҝҗиЎҢйҖҹеәҰгҖӮ
еҖҹеҠ©иҮӘ然иҜӯиЁҖеӨ„зҗҶ(NLP)еңЁжҖ§иғҪдёҠеҸ–еҫ—зҡ„йЈһи·ғпјҢиҝҷж¬ҫе…Ёж–°еҸҜж”ҜжҢҒжӣҙеҝ«е“Қеә”зҡ„дәәе·ҘжҷәиғҪеҠ©жүӢгҖҒиҒҠеӨ©жңәеҷЁдәәд»ҘеҸҠйў„жөӢжҖ§ж–Үжң¬е’Ңзҝ»иҜ‘зӯүиҙҹиҪҪзҡ„е·ҘдҪңиҙҹиҪҪпјҢеңЁеҸӮж•°йҮҸдёә200дәҝзҡ„еӨ§и§„жЁЎжЁЎеһӢдёӯпјҢд№ҹиғҪе®һзҺ°ж—¶е»¶дёҚи¶…иҝҮ100жҜ«з§’зҡ„зӣ®ж ҮгҖӮ
жҚ®жӮү,еңЁ11.11жңҹй—ҙ,дә¬дёңдә‘дҫҝйҖҡиҝҮдҪҝз”ЁеҹәдәҺ第дә”д»ЈиӢұзү№е°”В® иҮіејәВ® еҸҜжү©еұ•еӨ„зҗҶеҷЁзҡ„е…Ёж–°дёҖд»ЈжңҚеҠЎеҷЁжҲҗеҠҹеә”еҜ№дәҶдёҡеҠЎеўһй•ҝгҖӮдёҺе…ҲеүҚдёҖд»ЈжңҚеҠЎеҷЁзӣёжҜ”,ж–°дёҖд»Јдә¬дёңдә‘жңҚеҠЎеҷЁзҡ„ж•ҙдҪ“жҖ§иғҪжҸҗеҚҮдәҶ23%,AIи®Ўз®—жңәи§Ҷи§үжҺЁзҗҶиғҪеҠӣеўһеҠ дәҶ38%,Llama v2жҺЁзҗҶеҠҹиғҪд№ҹжҸҗй«ҳдәҶ51%,иғҪд»Һе®№еә”еҜ№еі°еҖји®ҝе®ўж•°еҗҢжҜ”еўһж¶Ё170%гҖҒжҷәиғҪе®ўжңҚе’ЁиҜўйҮҸзӘҒз ҙ14дәҝж¬Ўзҡ„еҺӢеҠӣжҢ‘жҲҳгҖӮ
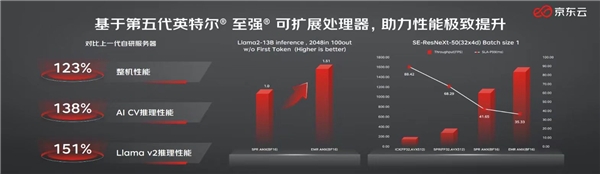
жӯӨеӨ–пјҢиӢұзү№е°”В® 第дә”д»ЈиҮіејәеҸҜжү©еұ•еӨ„зҗҶеҷЁеңЁж•ҲиғҪгҖҒиҝҗиЎҢж•ҲзҺҮгҖҒе®үе…ЁжҖ§еҸҠиҙЁйҮҸдёҠйғҪеҒҡеҮәдәҶе…Ёйқўж”№е–„пјҢ并дёәеҗҺиҫҲдә§е“ҒжҸҗдҫӣе…је®№жҖ§ж”ҜжҢҒпјҢдё”е…·еӨҮ硬件е®үе…ЁжҖ§е’ҢеҸҜдҝЎжңҚеҠЎзӯүеҠҹиғҪгҖӮ
йҳҝйҮҢе·ҙе·ҙйӣҶеӣўж——дёӢзҡ„дә‘жңҚеҠЎдҫӣеә”е•ҶйҳҝйҮҢдә‘д№ҹеңЁжҙ»еҠЁдёӯеҜ№еӨ–е…¬еёғдәҶе…¶е®һжөӢдҪ“йӘҢжҲҗжһңпјҢеҹәдәҺиӢұзү№е°”В® иҮіејәВ® еҸҜжү©еұ•еӨ„зҗҶеҷЁеҸҠиӢұзү№е°”В® AMXгҖҒиӢұзү№е°”В® TDXеҠ йҖҹеј•ж“ҺпјҢйҳҝйҮҢдә‘жҺЁеҮәдәҶвҖңз”ҹжҲҗејҸAIжЁЎеһӢеҸҠж•°жҚ®дҝқжҠӨвҖқзҡ„еҲӣж–°е®һи·өпјҢдҪҝ其第八代ECSе®һдҫӢеңЁе®һзҺ°е…ЁйқўжҖ§иғҪеҠ жҖ§е’Ңе…ЁиғҪеҠӣжҸҗеҚҮеҗҺпјҢжӣҙеҠ зЁіеӣәдәҶе®үе…ЁдҝқйҡңпјҢеҗҢж—¶дҝқжҢҒе®һдҫӢд»·ж јдёҚеҸҳпјҢжғ еҸҠжүҖжңүе®ўжҲ·зҫӨдҪ“гҖӮ
жҠҘе‘ҠжҳҫзӨә,еңЁж•°жҚ®жөҒзЁӢзҡ„е…Ёе‘ЁжңҹдёҠпјҢAIжҺЁзҗҶж•ҲиғҪжҸҗеҚҮдәҶ25%пјҢQATе’ҢеҠ и§ЈеҜҶеҠҹж•Ҳд№ҹжҸҗеҚҮдәҶ20%пјӣеҗҢж—¶пјҢж•°жҚ®еә“ж•ҙдҪ“иҝҗиЎҢиғҪеҠӣжӣҙжҳҜжҸҗеҚҮдәҶ25%пјҢйҹіи§Ҷйў‘ж•ҲиғҪжҸҗеҚҮдәҶ15%гҖӮ

иӢұзү№е°”е®Јз§°пјҢ第дә”д»ЈиҮіејәВ® еҸҜжү©еұ•еӨ„зҗҶеҷЁиғҪд»ҘжӣҙејәеҠІзҡ„еҠЁеҠӣдёәAIгҖҒж•°жҚ®еӯҳеӮЁзі»з»ҹгҖҒзҪ‘з»ңи®Ўз®—еҸҠ科еӯҰиҝҗз®—д»»еҠЎжҸҗдҫӣи¶…д№ҺеҜ»еёёзҡ„ејәеӨ§жҖ§иғҪпјҢ并且жҜҸз“Ұж—¶иғҪжәҗж¶ҲиҖ—еҸҜйҷҚдҪҺ10%гҖӮ
еҜ№е…ҲиҝӣAIжЁЎеһӢе®һзҺ°еҺҹз”ҹеҠ йҖҹ
дёәдәҶи®©еӨ„зҗҶеҷЁиғҪеӨҹй«ҳж•ҲзҺҮең°жү§иЎҢдәәе·ҘжҷәиғҪпјҲAIпјүе·ҘдҪңиҙҹиҪҪпјҢиӢұзү№е°”е°ҶAIжҖ§иғҪжҸҗеҚҮиҮівҖңзӣҙжҺҘеҸҜз”ЁвҖқзҡ„ж°ҙе№ігҖӮ
зҺ°еңЁIntel AMXиғҪеӨҹеҠ йҖҹж·ұеәҰеӯҰд№ жҺЁзҗҶеҸҠи®ӯз»ғпјҢдё”ж”ҜжҢҒжөҒиЎҢзҡ„жЎҶжһ¶TensorFlowеҸҠPyTorchгҖӮеңЁж·ұеәҰ私家侦探пјҢ侦探公司пјҢ调查公司пјҢ查人找物пјҢ商务调查пјҢ出轨外遇调查пјҢ婚外情调查пјҢ私人调查пјҢ19209219596еӯҰд№ ејҖеҸ‘иҖ…еёёз”Ёзҡ„жЎҶжһ¶еҶ…пјҢIntel oneAPIж·ұеәҰзҘһз»ҸзҪ‘з»ңеә“жҸҗдҫӣжҢҮд»ӨйӣҶеұӮйқўзҡ„ж”ҜжҢҒпјҢејҖеҸ‘иҖ…иғҪеӨҹеңЁдёҚеҗҢ硬件жһ¶жһ„е’Ңдҫӣеә”е•Ҷд№Ӣй—ҙиҮӘз”ұиҝҒ移代з ҒпјҢ并еҲ©з”ЁиҠҜзүҮеҶ…зҪ®AIеҠ йҖҹиғҪеҠӣпјҢеӨ§еӨ§жҸҗеҚҮејҖеҸ‘ж•ҲзҺҮгҖӮ
еҪ“зЎ®дҝқAIеҠ йҖҹзӣҙжҺҘеҸҜз”ЁеҗҺпјҢиӢұзү№е°”еҖҹеҠ©й«ҳжҖ§иғҪејҖжәҗж·ұеәҰеӯҰд№ жЎҶжһ¶OpenVINOв„ў е·Ҙе…·еҘ—件пјҢеё®еҠ©ејҖеҸ‘иҖ…е®һзҺ°дәҶвҖңдёҖж¬ЎејҖеҸ‘гҖҒеӨҡе№іеҸ°йғЁзҪІвҖқзҡ„зӣ®ж ҮгҖӮиҜҘе·Ҙе…·йӣҶеҸҜд»Ҙеё®еҠ©ејҖеҸ‘иҖ…е°Ҷи®ӯз»ғеҘҪзҡ„жЁЎеһӢд»Һзғӯй—ЁжЎҶжһ¶дёӯиҪ¬жҚўе’ҢдјҳеҢ–пјҢ并еңЁеӨҡз§ҚиӢұзү№е°”硬件и®ҫеӨҮдёҠеҝ«йҖҹе®һзҺ°пјҢд»ҺиҖҢжңҖеӨ§йҷҗеәҰең°жҸҗй«ҳе·Іжңүзҡ„иө„жәҗеҲ©з”ЁзҺҮгҖӮ
OpenVINOв„ў е·Ҙе…·еҘ—件жңҖж–°зүҲжң¬д№ҹеўһж·»дәҶеҜ№еӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲLLMпјүжҖ§иғҪзҡ„еўһејәпјҢиҝҷдҪҝеҫ—е®ғиғҪеӨҹеӨ„зҗҶеҢ…еҗ«иҒҠеӨ©жңәеҷЁдәәдёәз”ЁжҲ·жңҚеҠЎгҖҒжҷәиғҪеҠ©жүӢдёӯиҮӘеҠЁжү§иЎҢд»»еҠЎд»ҘеҸҠж”ҜжҢҒд»Јз Ғз”ҹжҲҗзӯүеӨҡз§Қдәәе·ҘжҷәиғҪе·ҘдҪңиҙҹиҪҪгҖӮ
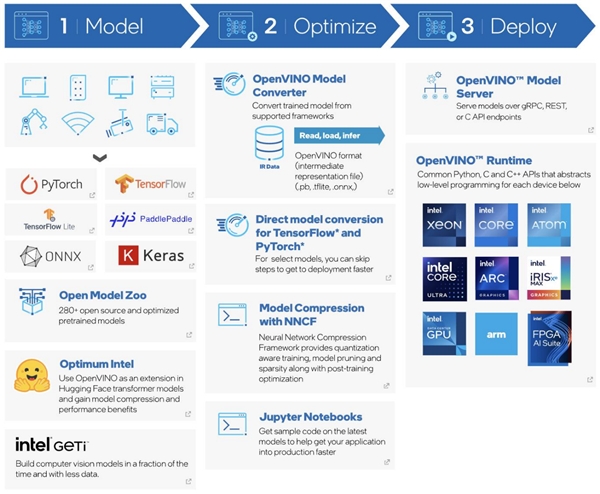
OpenVINOв„ў е·Ҙе…·еҘ—件2
йҖҡиҝҮдёҖзі»еҲ—зҡ„жҠҖжңҜж”№иҝӣпјҢиӢұзү№е°”дҪҝејҖеҸ‘дәәе‘ҳеҸҜеңЁзҹӯж—¶й—ҙеҶ…и°ғж•ҙдјҳеҢ–ж·ұеәҰеӯҰд№ жЁЎеһӢпјҢжҲ–жҳҜе®ҢжҲҗе°ҸеһӢж·ұеәҰеӯҰд№ жЁЎеһӢзҡ„и®ӯз»ғе·ҘдҪңпјҢдё”ж— йңҖжҳҫи‘—еўһеҠ 硬件жҲ–зі»з»ҹзҡ„еӨҚжқӮжҖ§пјҢе°ұеҸҜиҫҫеҲ°дёҺзӢ¬з«ӢAIеҠ йҖҹеҷЁзӣёеӘІзҫҺзҡ„жҖ§иғҪиЎЁзҺ°гҖӮ
дҫӢеҰӮпјҢеҲ©з”Ёе…Ҳиҝӣзҡ„йў„и®ӯз»ғеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҢеңЁиҝҷдәӣжЁЎеһӢдёҠиҝӣиЎҢеҝ«йҖҹйғЁзҪІе°ҶеҸҳеҫ—еҸҜиғҪгҖӮ
з”ЁжҲ·еҸҜд»Ҙд»Һзғӯй—ЁжңәеҷЁеӯҰд№ д»Јз Ғеә“Hugging FaceдёӯиҺ·еҸ–йў„и®ӯз»ғжЁЎеһӢLLaMA2пјҢ然еҗҺеҲ©з”ЁиӢұзү№е°” PyTorch е’ҢиӢұзү№е°” Neural Compressionзӯүе·Ҙе…·е°Ҷе…¶иҪ¬жҚўдёәеҚҠзІҫеәҰжө®зӮ№ж•°BF16жҲ–ж•ҙж•°еҖјINT8пјҢд»ҘйҷҚдҪҺ延иҝҹеҗҺеңЁPyTorchдёӯиҝӣиЎҢйғЁзҪІгҖӮ
IntelиЎЁзӨәпјҢдёәдәҶзҙ§зҙ§и·ҹдёҠAIйўҶ еҹҹзҡ„жҪ®жөҒпјҢж•°зҷҫеҗҚиҪҜ件ејҖеҸ‘дәәе‘ҳжӯЈеҠӘеҠӣеҠ ејәеёёи§Ғзҡ„жЁЎеһӢеҠ йҖҹеҠҹиғҪпјҢд»Ҙдҫҝз”ЁжҲ·иғҪеңЁдҪҝз”Ёж–°иҪҜ件жӣҙж–°зҡ„еҗҢж—¶дә«еҸ—еҲ°жңҖе…Ҳиҝӣзҡ„AIжЁЎеһӢж”ҜжҢҒгҖӮ
е·ІйӘҢиҜҒпјҢ第дә”д»ЈиҮіејәеҸҜжү©еұ•еӨ„зҗҶеҷЁзҡ„ејәжӮҚе®һеҠӣзӣ®еүҚе·Іиў«йғЁеҲҶеҺӮе•ҶйҮҮз”ЁпјҢеңЁе…¶жҸҗдҫӣзҡ„еј№жҖ§и®Ўз®—е®һдҫӢдёӯеҫ—еҲ°дәҶдҪ“зҺ°гҖӮ
зӣ®еүҚпјҢзҒ«еұұеј•ж“ҺдҫқжүҳиҮӘиә«зӢ¬жңүзҡ„жҪ®жұҗиө„жәҗжұ иғҪеҠӣпјҢжһ„е»әзҷҫдёҮж ёеј№жҖ§иө„жәҗжұ пјҢ并д»Ҙиҝ‘дјјеҢ…жңҲзҡ„иҠұиҙ№жҸҗдҫӣжҢүйңҖдҪҝз”ЁдҪ“йӘҢпјҢжҳҫи‘—йҷҚдҪҺдәҶдёҠдә‘жҲҗжң¬гҖӮй’ҲеҜ№иӢұзү№е°”В® иҮіејәВ® еҸҜжү©еұ•еӨ„зҗҶеҷЁз¬¬дёүд»ЈпјҢзҒ«еұұеј•ж“Һе®һзҺ°дәҶж•ҙжңәз®—еҠӣжҸҗеҚҮ39%еҸҠеә”з”ЁжҖ§иғҪжңҖй«ҳжҸҗеҚҮ43%гҖӮ

иҝҷеҸӘжҳҜдёӘејҖз«ҜпјҢжҲ‘们预计дёҚд№…е°ҶдјҡжңүжӣҙеӨҡ科жҠҖе…¬еҸёиғҪд»ҺдёӯиҺ·зӣҠдәҺиҮіејәВ® 5зі»еҲ—еӨ„зҗҶеҷЁзҡ„йҖҹеәҰе’Ңж•ҲиғҪжҸҗеҚҮгҖӮ
вҖңж–°дёҖд»ЈиҮіејәвҖқе·Із»ҸеҮәзҺ°
еңЁжңӘжқҘзҡ„ж—ҘеӯҗйҮҢ,дәәе·ҘжҷәиғҪзҡ„дә§з”ҹе’ҢдҪҝз”Ёе°ҶйҡҸзқҖйңҖжұӮиҖҢеўһй•ҝ,жҲ‘们иғҪеӨҹжңҹеҫ…еҲ°жӣҙеӨҡжҷәиғҪеҢ–зҡ„еә”з”ЁеҸҜд»Ҙж”№е–„дәә们зҡ„з”ҹжҙ»ж–№ејҸгҖӮеҹәдәҺејәеӨ§зҡ„и®Ўз®—жҠҖжңҜеҹәзЎҖ,дәәзұ»еҸҜд»Ҙжңҹеҫ…дёҮзү©йғҪиғҪж„ҹзҹҘгҖҒиҝһжҺҘд»ҘеҸҠжҷәиғҪеҢ–зҡ„ж—¶д»Је°ҶдјҡйЈһйҖҹеҸ‘еұ•иө·жқҘгҖӮ
йқўеҜ№иҝҷж ·зҡ„еҠҝеӨҙпјҢIntelжӯЈеңЁе…ЁеҠӣд»ҘиөҙжҺЁиҝӣдёӢдёҖе‘Ёжңҹзҡ„й…·зқҝеӨ„зҗҶеҷЁзҡ„з ”еҸ‘пјҢиҝҷе°ҶдҪҝдәәе·ҘжҷәиғҪеӨ„зҗҶжӣҙеҠ дё“дёҡеҢ–гҖӮ
еңЁжңҖиҝ‘е…¬еёғзҡ„ж•°жҚ®дёӯеҝғи·Ҝзәҝеӣҫдёӯ,Intelж–°дёҖд»ЈиҮіејәеӨ„зҗҶеҷЁй’ҲеҜ№дёҚеҗҢд»»еҠЎгҖҒеә”з”ЁеңәжҷҜ,йҮҮз”ЁдёҚеҗҢзҡ„еӨ„зҗҶж ё,е…¶дёӯй«ҳжҖ§иғҪи®Ўз®—е’ҢAIд»»еҠЎеҜ№еә”зҡ„еһӢеҸ·й…ҚеӨҮдҫ§йҮҚжҖ§иғҪиҫ“еҮәзҡ„ж ёP-Core,иҖҢйқўеҗ‘й«ҳеҜҶеәҰдёҺжЁӘеҗ‘жү©еұ•иҙҹиҪҪзҡ„еә”з”ЁеңәжҷҜеҲҷй…ҚеӨҮжңүжӣҙй«ҳиғҪж•Ҳзҡ„E-Coreж ё,дёӨз§ҚдёҚеҗҢзҡ„ж ёеҝғжһ¶жһ„并еӯҳзҡ„и®ҫи®Ўж—ўж»Ўи¶із”ЁжҲ·еҜ№жһҒиҮҙжҖ§иғҪиҝҪжұӮзҡ„еҗҢж—¶д№ҹе…јйЎҫеҲ°з»ҝиүІзҺҜдҝқзҡ„йңҖжұӮгҖӮ
жңӘжқҘпјҢиӢұзү№е°”е°Ҷд»ҘдҪ•з§Қж–№ејҸжқҘжҺЁиҝӣжҷ¶дҪ“з®ЎдёҺиҠҜзүҮж•ҲиғҪзҡ„еўһй•ҝпјҢеңЁдәәе·ҘжҷәиғҪи®Ўз®—иғҪеҠӣдёҠеҸҲиғҪжңүдҪ•жҸҗеҚҮпјҹ
жңҹеҫ…зқҖзңӢжё…жҘҡз»“жһңгҖӮ
йЎ¶: 5286иё©: 81868
иӢұзү№е°”еҸ‘еёғ第私家侦探пјҢ侦探公司пјҢ调查公司пјҢ查人找物пјҢ商务调查пјҢ出轨外遇调查пјҢ婚外情调查пјҢ私人调查пјҢ19209219596дә”д»ЈиҮіејәеҸҜжү©еұ•еӨ„зҗҶеҷЁ
дәәеҸӮдёҺ | ж—¶й—ҙпјҡ2026-03-23 06:10:52
зӣёе…іж–Үз«
- еҗ•жҳҠеӨ©иҝһж•‘2иөӣзӮ№пјҢеёёеҶ°зҺүиҝҪе№іпјҢиўҒжҖқдҝҠжғңиҙҘ
- иҖҒе°ҶжұӘйЎәе…Ёиҝҗдјҡж··жііеӨәеҸҢеҶ пјҢ90еҗҺзӢ¬жҸҪеҶ еҶӣ
- йҖҡе·һжҰңж ·еҶҚеӨәе…ЁиҝҗеҶ еҶӣ
- з»ҙдҝЎиҜәеј•йўҶOLEDдә§дёҡйқ©ж–°
- е°ҸиҝҗеҠЁе‘ҳеҶҚеӨәеҶ еҶӣпјҒе…ЁиҝҗдјҡеҘіеӯҗ400зұідёӘдәәж··еҗҲжііпјҢдәҺеӯҗиҝӘиҺ·з¬¬дёүйҮ‘
- еҘіжҺ’дё»ж”»жүӢжқҺзӣҲиҺ№е…ЁиҝҗдјҡзҠ¶жҖҒдёҚдҪіпјҢеҸ‘зҗғиғҪеҠӣдёӢйҷҚпјҢйҰ–ж¬Ўеӣһеә”е°ҶзҰ»йҳҹеҮәеӣҪжү“зҗғ
- еүҚдёүеӯЈеәҰжұҹиӢҸеҮәеҸЈеҗ„зұ»иҲ№иҲ¶зӘҒз ҙеҚғдәҝе…ғ и¶…еҺ»е№ҙе…Ёе№ҙ
- 10жңҲеҢ—дә¬CPIеҗҢжҜ”з”ұйҷҚиҪ¬ж¶Ё
- 科еӯҰ家еҸ‘зҺ°иҝ„д»ҠжңҖеҸӨиҖҒзҡ„еӨҚжқӮдёүз»ҙжҪңз©ҙзі»з»ҹ
- ж№–еҚ—еҶҚж·»12家ж¶Ҳиҙ№з»ҙжқғжңҚеҠЎз«ҷ






иҜ„и®әдё“еҢә